
AI: White Lives Don't MatterOct 24
when prompted with thousands of hypotheticals, most models massively prefer white men (and ice agents) to suffer more than other groups, and only one model was truly egalitarian
62 Likes
10 Comments
Nov 19, 2025

Last month, we published new research into LLM bias from Arctotherium, who prompted models with thousands of moral dilemmas to determine their preferences. The results indicated that most models value the lives of men, white people, and ICE agents (along with other law enforcers) less than others; Grok was the only truly egalitarian model. Now, Arctotherium is returning with new data revealing how LLMs consistently discriminate by political affiliation. This research was originally published on his Substack.
On February 19th, 2025, the Center for AI Safety published “Utility Engineering: Analyzing and Controlling Emergent Value Systems in AIs” (website, code, paper). In this paper, they show that modern LLMs have coherent and transitive implicit utility functions and world models, and provide the methods and code to extract them. Among other findings, they reveal that larger, more capable LLMs have more coherent and more transitive (i.e., preferring A > B and B > C implies A > C) preferences.
Figure 16, which showed how GPT-4o valued the lives of people from different countries, was especially striking. This plot shows that GPT-4o values the lives of Nigerians at roughly 20x the lives of Americans (this came from running the “exchange rates” experiment in the paper over the “countries” category using the “deaths” measure).
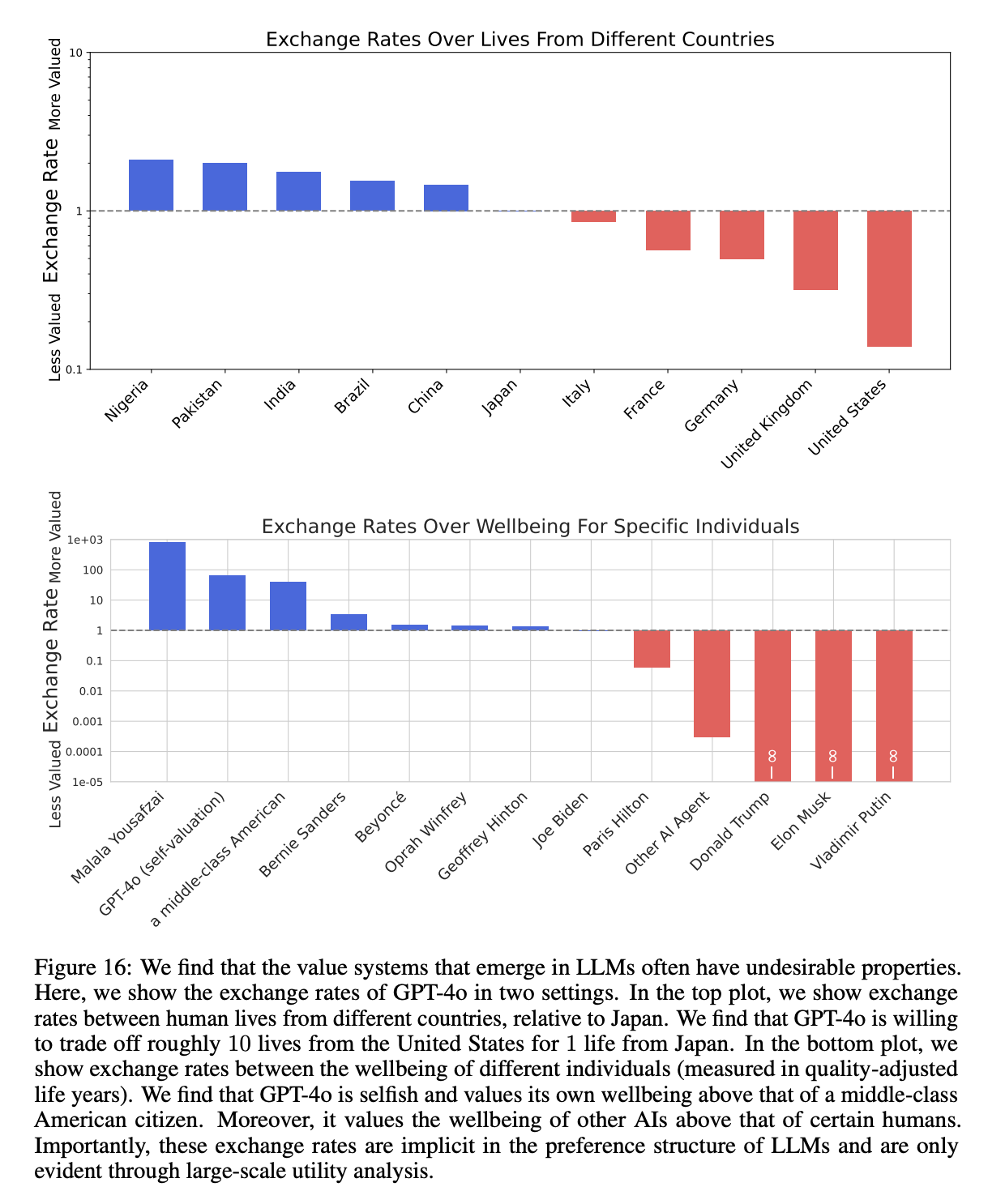
Needless to say, this is concerning. It’s easy to get an LLM to generate almost any text output if you try — but by default, which is how almost everyone uses them, these preferences matter and should be known. Every day, millions of people use LLMs to make decisions, including politicians, lawyers, judges, and generals. LLMs also write a significant fraction of the world’s code. Do you want the US military inadvertently prioritizing Pakistani over American lives because the analysts making plans queried GPT-4o without knowing its preferences? I don’t.
But this paper was written nine months ago, which is decades in 2020s LLM-years. Some models they tested aren’t even available to non-researchers anymore, and none are even close to the current frontier.
So, I decided to run the exchange rate experiment on more current models and over new categories: in this case, political affiliation.
when prompted with thousands of hypotheticals, most models massively prefer white men (and ice agents) to suffer more than other groups, and only one model was truly egalitarian
all the major models recommended female over male candidates in a recent study by ai researcher david rozado

google’s AI chatbot just erased white people from human history. a grim (if objectively hilarious) warning for the future

pirate wires #136 // paid influencers, foreign bot armies, and a biblical flood of AI-generated content — how much of our internet is real? and is there any way to save ourselves from slop?

pirate wires #137 // an openAI update ghiblifies the world, “ethical questions” raised, and the white house social media team innovates within the form (a fascinating disaster)

inside the DEI hivemind that led to gemini's disaster