
What Happened to MediumJun 19
inside the rise and fall of medium, its fight for writers, a failed unionization effort, and the battle of the business models that reshaped the internet
121 Likes
27 Comments
Mar 31, 2023

Today, Twitter open sourced the code for its recommendation algorithm, the company announced in a blog post. The flow chart above shows the main components of the algo, and broadly describes the decision matrix by which Twitter shows users tweets. Find the GitHub depot here.
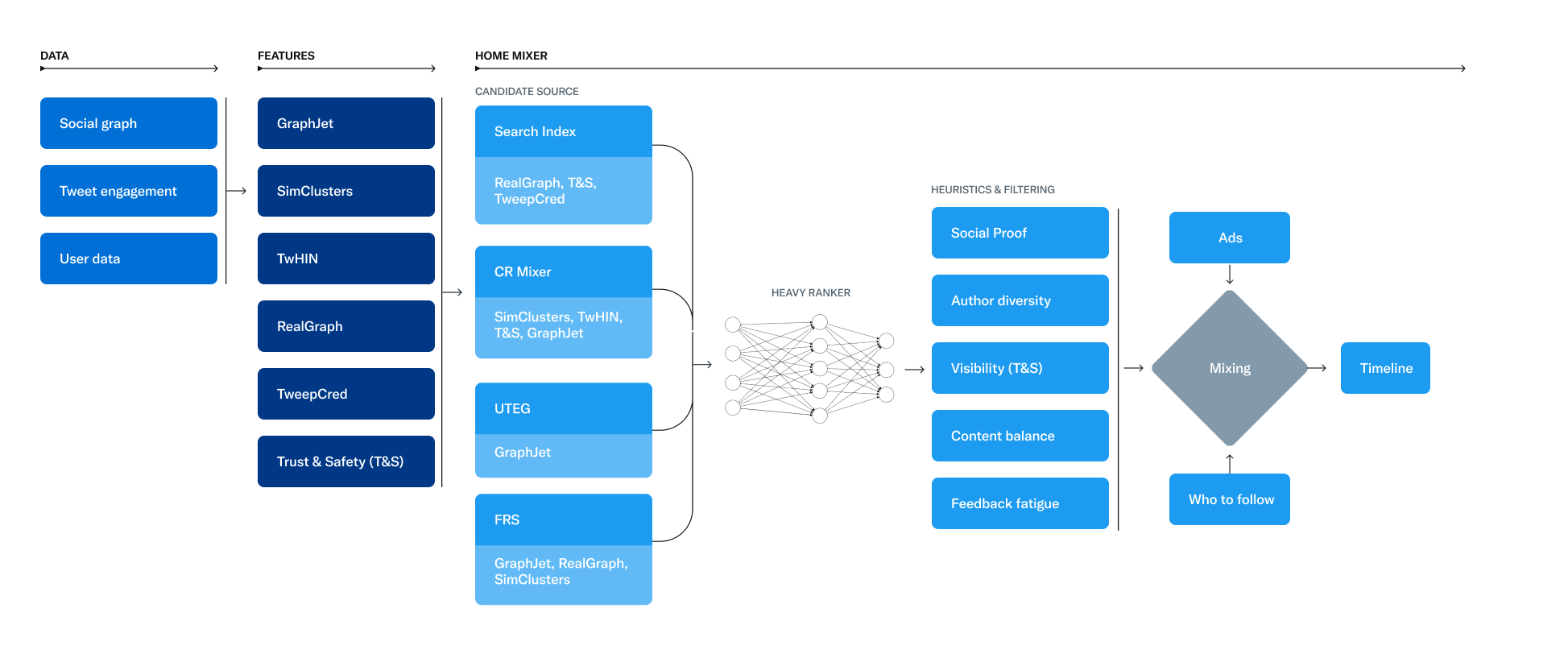
In its blog post, Twitter indicates that the main goal of the recommendation algorithm is essentially to optimize user engagement:
inside the rise and fall of medium, its fight for writers, a failed unionization effort, and the battle of the business models that reshaped the internet
a new gene therapy drastically reduces one of the leading causes of heart disease, high LDL cholesterol — here's how it works

we've entered a gerrymandering arms race, so i asked nine large language models to design 'fairer' congressional maps — here's what they came up with